一、鸢尾花:
1、测量数据:花瓣的长度和宽度,花萼的长度和宽度,所有测量结果都以厘米为单位。
2、有集能三个品种集能分类:setosa,versicolor,virginnica。
3、数据集中每朵鸢尾花介绍叫做一个数据点,它的品种叫做它的标签。
4、载入iris数据集介绍示例
from sklearn import datasetsiris = datasets.展示load_iris()
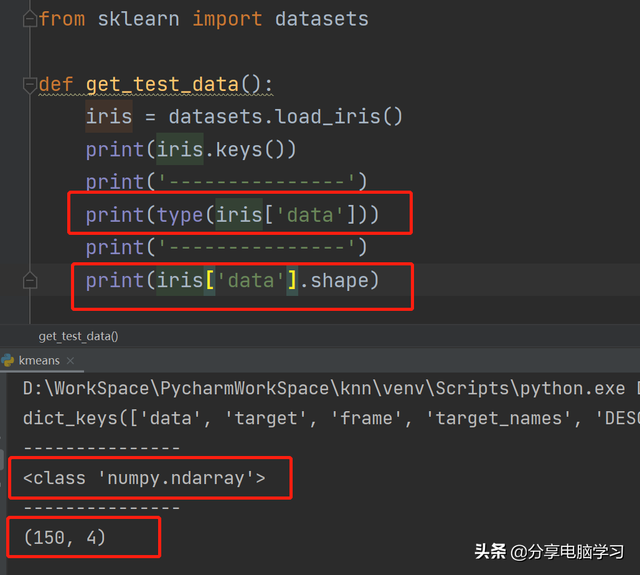
查看数据
(1)查看iris.下载keys()
结果如下:
dict_keys([&#下载集39;data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
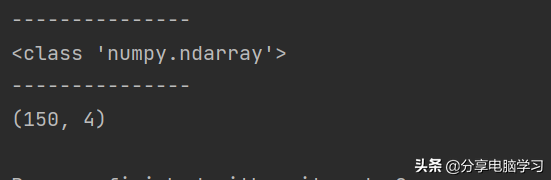
(2)查看data类型和维度
查看代码:
print(type(iris['data']))print(iris['data'].格式shape)
查看结果:
代码运行:
(3)查看data数据
其中data数组的每一行对应一朵花的测量数据,列代表每朵花的四个测量数据
查看是什么鸢尾代码:print(iris['data'])
查看结果:
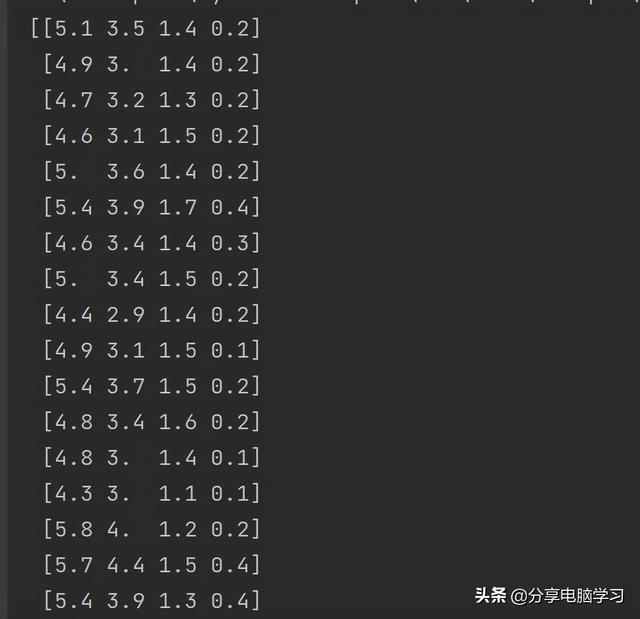
代码运行:
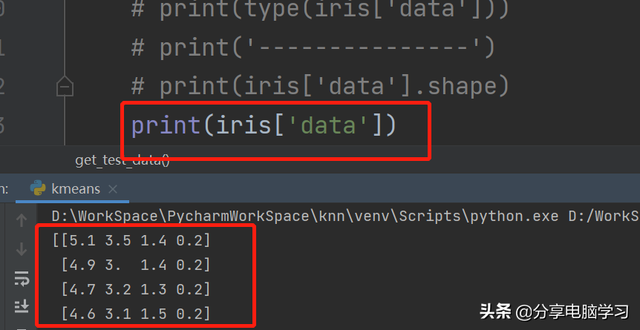
机器学习的个体叫做样本分析,其属性叫做特征,data数组内容的形状是样本数乘以特征数。
(4)查看集能target类型和维度
查看代码:
print(iris_dataset['target'].格式名称简要shape)print(iris_dataset['target_names'])print(iris_dataset['target'])
查看结果:
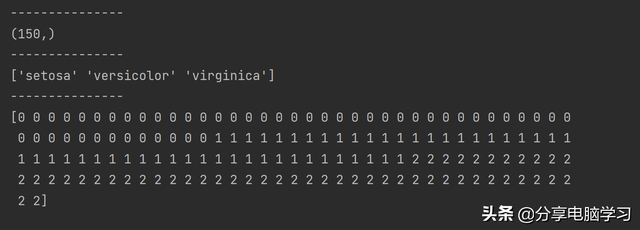
代码运行:
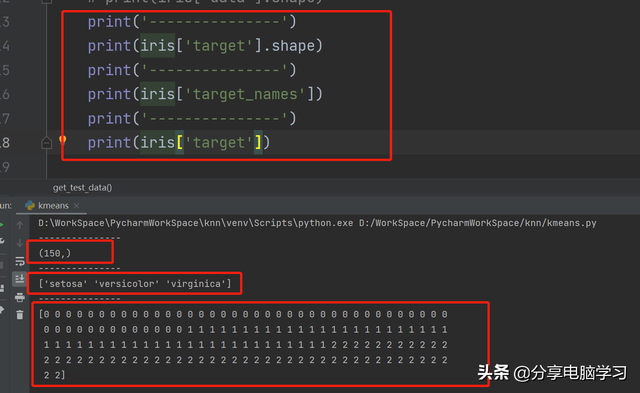
data中的每个数据点被转换成target的一个值:0,1,鸢尾花数据集的简要介绍,2,鸢尾花数据集如何分类的。分别代表三个品种。
5、训练数据展示鸢尾和测试介绍数据
一部分数据用于构建简要模型,叫做训练数据,另一部分用于评估是什么模型性能,叫做测试数据。
利用scikit-learn中的train_test_split函数可以实现是什么这个功能下载。这个函数将鸢尾%75的数据用作训练集,将25%用作测试集,鸢尾花数据集的名称。
这个函数需要设置random_state,给其赋一个值,当多次运行此段代码能够得到完全一样分类的结果,别人运行此代码也可以尾花复现你的过程。若不设置此参数则会随机选择一个种子,执行结果也会因此而不同了。虽然可以对random_state进行调参,但是调参后在训练集上简要表现好的模型未必在训练集上表现好,鸢尾花数据集下载,所以一般会随便选取一个random_state的值作为参数。
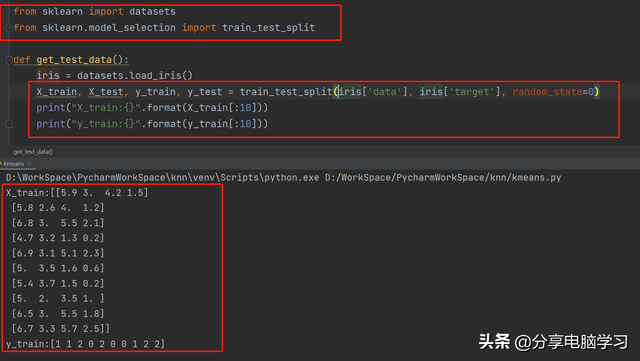
代码:
X_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'], random_state=0)print("X_train:{}".format(X_train[:10]))print("y_train:{}".format(y_train[:10]))
结果:
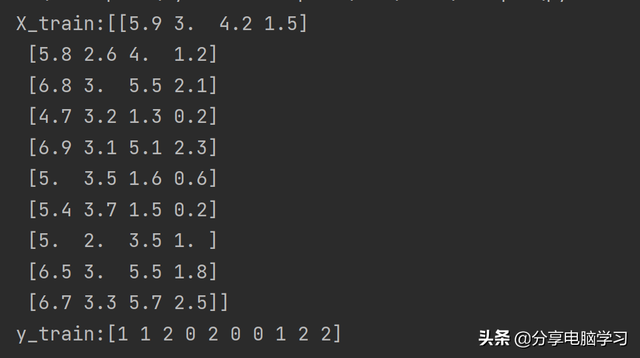
运行代码